Agents write the code. Intent and evidence are your job.
Waterfall, Agile, and Scrum were scaffolding for human limitations. Agents don't have those limitations. Ideas 2 Execution is the loop that's left — declare the intent, let agents build, force the evidence, adapt — and never stop.
Private early access · No CI, no daemon, no ceremony
code-generatedAgentpytestno-open-redirectAgentpytestredirect-latency-p95Agent+Providerdatadogbrand-feelAgent+ProviderhumanOne loop. Four phases. It never ends.
Ideas 2 Execution runs the IDEA loop — the whole development lifecycle, minus the ceremony.
Targets that come back unmet feed the next loop. A fixed bug becomes a Case that gates every future build. The loop never ends — that's the point.
Your methodology was a workaround for being human.
Every process the industry adopted in the last forty years exists to compensate for a human limitation. Agents don't share those limitations — so the process became overhead.
Humans can't hold an entire system in their head.
Waterfall froze the spec up front so no one had to.
Agents hold the whole codebase in context. A frozen spec is just stale.
Humans misjudge scope and miscommunicate intent.
Agile shipped in small increments to catch the drift early.
Agents land a change in minutes. The increment is now a single loop.
Humans lose context and forget to coordinate.
Scrum added standups, planning, and retros to re-sync the team.
Agents don't lose context and don't attend standups. The ceremony is pure cost.
Humans make mistakes line by line.
Code review put a second human in front of every diff.
No human reads most of the diff anymore. Line-by-line review can't scale to agent output.
Strip away the scaffolding and two things remain — the two things every process was ever a proxy for: did we build what we meant to (intent), and is there proof it works (evidence)?
An AI that writes its own tests will pass its own tests.
That isn't a failure. It's exactly what the model is built to do.
A model optimizes for the signal you hand it. When it also gets to define that signal, a green suite proves nothing — it's the agent grading its own homework. Velocity measured against self-authored tests is theater: you can ship a thousand passing checks and move no metric that matters. I2E forces the evidence apart from the agent by splitting it in two.
What the agent can prove.
A check the agent fully controls and runs on demand — a unit test, an API probe, a type-check. Deterministic, repeatable, and yes, often agent-authored. Cases gate the ship. But passing every Case you wrote is the floor, not the finish line.
What the agent cannot fake.
A verdict that lives outside the agent's reach — an external metric, a measurement that needs time to elapse, or a human's judgment. The agent can't write a Target green. Targets are where you learn whether the work actually moved the needle.
Cases keep the build honest. Targets keep the business honest.
A live, interactive view of the loop.
Ideas 2 Execution comes with a web console to monitor every agent, drill into the evidence, and force the verdicts that only you can give.
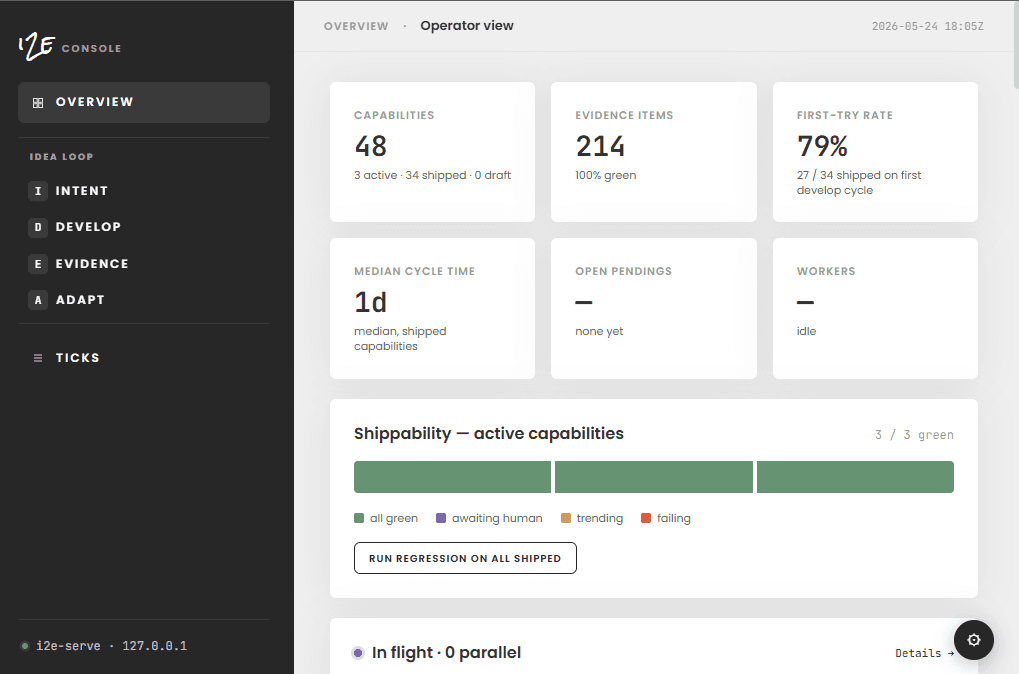
A harness for code no human will read.
When agents write in parallel and humans review almost none of it, you need somewhere to stand. I2E is that vantage point.
Forced evidence
Every Capability names a provider for each claim of success. You cannot declare a result you have no way to collect. No aspirational metrics — ever.
Cases vs. Targets
The framework separates what an agent can verify itself from what only an external system, the passage of time, or a person can confirm. Self-grading can't hide here.
Parallel agent loops
An orchestrator plans a batch of non-conflicting Capabilities each tick and runs them in isolated worktrees. Agents just write code — the framework keeps them from colliding.
Full agent visibility
See every in-flight agent, its current step and progress, and the evidence behind each verdict — drill from a green light down to the exact failing query.
A human evidence harness
Some proof only a person can give. A pending queue and a live dashboard are where humans mark, judge, and demonstrate the evidence an agent cannot produce.
The loop never ends
Bugs become permanent Cases. Unmet Targets reopen the loop. Code is an output that regenerates; your intents and evidence are what persist.
Expert knowledge, picked up automatically.
DESIGN.md, ARCHITECTURE.md, SECURITY.md — and anything else your domain experts care to drop in — live in /context. The framework reads them when it's planning, building, and grading evidence, so the rules in those documents shape every Capability without anyone having to repeat them. Write it once, and every agent in the loop respects it appropriately.
Velocity is not how much code you shipped. It's whether the code moved a metric you meant to move.
An agent can spend a million tokens producing a thousand green tests against a goal nobody set. That isn't speed — it's expensive motion. A real loop closes on intent and evidence: every cycle either moves the needle or tells you plainly that it didn't. When it didn't, you stop paying for it.
Less reviewing diffs. More steering intent.
“We had agents shipping code all day and no idea if any of it mattered. I2E made the question unavoidable — which Target did this move? Half our backlog quietly evaporated.”
“Our agents' test suites were always green. Always. The first time we forced Targets, we found three "done" features that moved nothing. That's the day the number started meaning something.”
“Four agents, four parallel loops, one dashboard telling me exactly what each is doing and what needs me. I stopped reviewing diffs and started steering intent.”
Frequently asked
Still curious? Reach us at hello@i2e.io.
We can teach your team to run the IDEA loop.
Half-day and multi-day workshops, in person or remote. We walk your engineers through declaring intent, wiring providers, and standing up the evidence harness in your own repos — so when we leave, the loop is running and your team owns it.
Scoped engagements from a single team kickoff to multi-week rollouts.